
AgentforceのPoCや実装を進める中で、「プロンプトを細かく調整しても、的外れな回答をする」「存在しない仕様をでっち上げる(ハルシネーション)」といった課題に直面することがあります。
これらの原因の多くは、AIの推論能力やプロンプトではなく、RAG(検索拡張生成)の源泉となるナレッジデータそのものの構造に起因しています。人間が読んで理解しやすいマニュアルをそのままData 360に投入しても、AIが正しく情報を引き出せるとは限りません。
本記事では、Salesforce Data 360の仕様(事実)と、それを踏まえた非構造化データの精緻化・最適化アプローチ(推測およびプラクティス)を整理します。
Data 360におけるRAGとチャンキングの仕様
Agentforceがナレッジを参照して回答を生成する際、背後ではData 360の検索インデックス(Search Index)が稼働しています。データがどのように処理されているかの仕様を把握することが、対策の第一歩となります。
非構造化データのチャンク化
Data 360にナレッジ記事やPDFなどの非構造化データを取り込むと、データは検索インデックスを作成するために「チャンク(Chunk)」と呼ばれる小さな意味のブロックに分割され、ベクトル化されます。
検索インデックスでは、文字数や特定の区切り文字に基づいてテキストを分割するアルゴリズムが採用されています。これは、AIが長大なドキュメント全体を一度に処理することはリソース効率や精度の面で適さないためです。結果として、1つの記事は必ず「前後の文脈が分断された細切れのデータ」としてデータベースに保存されます。
ベクトル検索とハイブリッド検索
ユーザーが質問をすると、質問文がベクトル化され、最も意味的に近いチャンクが検索・抽出されます。さらにSalesforceでは、ベクトル検索だけでなく、従来のキーワード検索や、メタデータ(作成日、カテゴリなど)による絞り込み(インデックス検索)を組み合わせる「ハイブリッド検索」の構成もサポートしています。
RAGに最適化されたデータの書き方
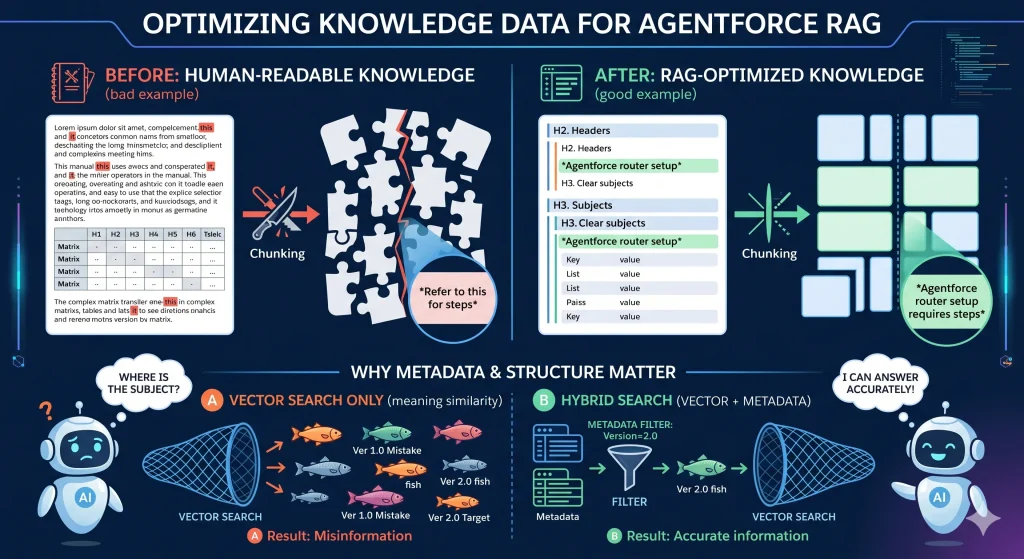
「強制的にチャンク化される」という仕様を踏まえると、RAG源泉データの最適な姿は「切り取られた一つのチャンクだけで、主語と文脈が独立して成立している状態」であると考えられます。
既存のナレッジをData 360へ連携する前に、以下の観点でデータの精緻化(リファクタリング)を行うことが有効です。
見出しによる階層化とチャンク境界の提示
意味の区切りが不明確なベタ打ちのテキストは、文脈の中途半端な位置で分断されるリスクが高まります。HTMLタグやMarkdownの見出しを用いて、ドキュメントの構造を明確にします。これにより、見出しとその直下の短い段落が1つのチャンクとして適切にまとまりやすくなります。
指示代名詞の排除と主語の補完
人間向けの文章では、「この機能の仕様は〜」といった指示代名詞や省略が頻繁に使われます。しかし、チャンクとして単独で抽出された際、AIは「この機能」が何を指しているのか判断できず、誤った推論を引き起こす原因になります。段落が切り離されても意味が通じるよう、「Agentforce Service Agentのルーティング仕様は〜」のように、段落ごとに具体的な固有名詞・主語を繰り返し記述します。
複雑な表のテキスト化
行と列が交差して初めて意味を成す二次元の表(例:縦軸にプロファイル、横軸に権限、セルに〇×が書かれたマトリクス表)は、テキストデータとして一次元にチャンク化される過程で構造が崩壊します。複雑な表は、AIが読み取りやすいフラットなリスト構造や、キー・バリュー形式(項目名:値)の箇条書きに書き下ろします。
- 変更前:表形式でのマトリクス表現
- 変更後:
[システム管理者] 権限A: 許可, 権限B: 許可といったプレーンテキストの繰り返し
メタデータの構造化とハイブリッド検索の活用
ベクトル検索は「意味の類似性」を測るのには優れていますが、「バージョン2.0向けの情報のみ」といった明確な条件での絞り込みには不向きです。テキスト本文の精緻化と並行して、Salesforce Knowledge記事の標準項目やカスタム項目を利用し、「対象製品」や「適用バージョン」といったメタデータを構造化データとして付与します。このメタデータを検索条件に組み込む(ハイブリッド検索)ことで、ベクトル検索によるハルシネーションを物理的にブロックすることが可能になります。
まとめ
Agentforceの自律的な対話能力を実務レベルで活かすためには、プロンプトのチューニング以前に、AIが解釈しやすいデータ構造を提供することが不可欠です。RAGの源泉データの構造化と精緻化は、PoCフェーズで最も時間を投資すべき重要なプロセスになります。
| 最適化の観点 | 人間向けドキュメント(非推奨) | RAGに最適化された姿(推奨アプローチ) | 背景にあるData Cloudの仕様(事実) |
|---|---|---|---|
| 1. 見出しによる階層化 | ベタ打ちの長い文章。太字や文字サイズといった視覚的な装飾だけで段落が区切られている。 | HTMLタグやMarkdown(<h2>, <h3>)を用いて、トピックごとに明確にブロック分けされている。 | チャンキングアルゴリズムは、見出し等の構造的タグを「意味の区切り(チャンク境界)」として認識し、分割単位を決定する。 |
| 2. 主語の独立 (Self-contained) | 「本機能は〜」「これによれば〜」といった指示代名詞や、文脈に依存した主語の省略が多用されている。 | 各段落(チャンク)が単独で切り取られても意味が通じるよう、毎段落に具体的な固有名詞・主語が記述されている。 | 検索インデックス作成時、ドキュメントは強制的に細切れのチャンクに分割されて保存されるため、前後の文脈が物理的に分断される。 |
| 3. 表(マトリクス)のテキスト化 | セル結合や、行・列の交差によって意味を成す二次元の複雑な表(マトリクス)が含まれている。 | 複雑な表を避け、フラットなリスト構造や、キー・バリュー形式(項目名:値)の箇条書きのテキストに展開されている。 | 非構造化データのインジェストにおいて、表データは一次元のプレーンテキストとして抽出されるため、二次元的な意味構造が失われる。 |
| 4. メタデータの構造化 | 「対象バージョン」や「製品カテゴリ」といった絞り込み条件が、テキスト本文の中にのみ記述されている。 | 本文の精緻化に加え、Knowledge記事の標準項目やカスタム項目に、構造化データとして分類メタデータが登録されている。 | ベクトル検索は「意味の類似性」で抽出を行うため、特定条件での除外や絞り込みを確実に行うには、メタデータによる事前フィルタリング(ハイブリッド検索)が必要となる。 |
参考URL
Hybrid Search Best Practices (Salesforce Help)

Chunking Strategies (Salesforce Help)

Retrieval Augmented Generation (Salesforce Help)



読者の声